SourceData-NLP
Integrando la curación en la publicación científica para entrenar modelos de IA
El dataset más grande de Reconocimiento de Entidades Nombradas (NER) y Vinculación de Entidades Nombradas (NEL) en ciencias biomédicas. Integrando curación lista para IA directamente en el flujo de trabajo de publicación en EMBO Press.
También disponible en:
🇬🇧Read in EnglishSourceData-NLP: Cuando la Publicación se Encuentra con la IA
¿Qué pasaría si pudiéramos capturar conocimiento estructurado de artículos científicos en el momento en que se publican, en lugar de extraerlos años después? Esa es la idea revolucionaria detrás de SourceData-NLP—el dataset más grande de Reconocimiento de Entidades Nombradas (NER) y Vinculación de Entidades Nombradas (NEL) en ciencias biomédicas hasta la fecha. El artículo está aprobado para publicación en la revista Bioinformatics de Oxford University Press.
La Visión: Publicación como Infraestructura de Conocimiento
La publicación científica ha sido el mecanismo principal de la humanidad para compartir conocimiento durante siglos. Sin embargo, este rico repositorio permanece bloqueado en texto no estructurado, requiriendo un esfuerzo enorme para extraer y organizar. SourceData-NLP reimagina este proceso al integrar curación lista para IA directamente en el flujo de trabajo de publicación en EMBO Press.
En lugar de anotar artículos retrospectivamente, trabajamos con los autores durante la revisión por pares para capturar datos estructurados como parte del proceso de publicación en sí. Este enfoque transforma la publicación científica de un archivo estático en una infraestructura de conocimiento viva y legible por máquinas.
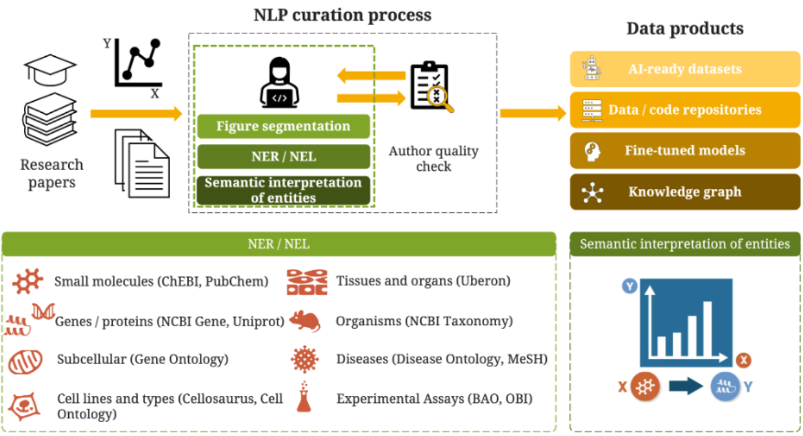
Figura 1: El flujo de trabajo de curación de SourceData-NLP. La integración de curación asistida por NLP en el proceso de publicación permite la captura de conocimiento estructurado de artículos de investigación. Los autores validan las anotaciones de entidades durante la revisión por pares, asegurando datos de entrenamiento de alta calidad. El proceso genera múltiples productos de datos incluyendo datasets listos para aprendizaje automático, modelos afinados y grafos de conocimiento semántico que conectan entidades biomédicas a través de la literatura.
Por los Números
SourceData-NLP no tiene precedentes en escala y alcance:
- 661,862 entidades anotadas en 8 categorías biomédicas
- 623,162 entidades vinculadas a ontologías y bases de datos externas
- 62,543 paneles de figuras anotados de 18,689 figuras científicas
- 3,223 artículos de investigación de 25 revistas líderes en biología molecular y celular
Pero el tamaño no lo es todo. Lo que hace único a SourceData-NLP es su enfoque en las leyendas de figuras—el núcleo narrativo de la evidencia científica donde se describen los resultados experimentales. A diferencia de los datasets construidos a partir de oraciones aisladas, SourceData-NLP preserva el rico contexto de la comunicación científica real.
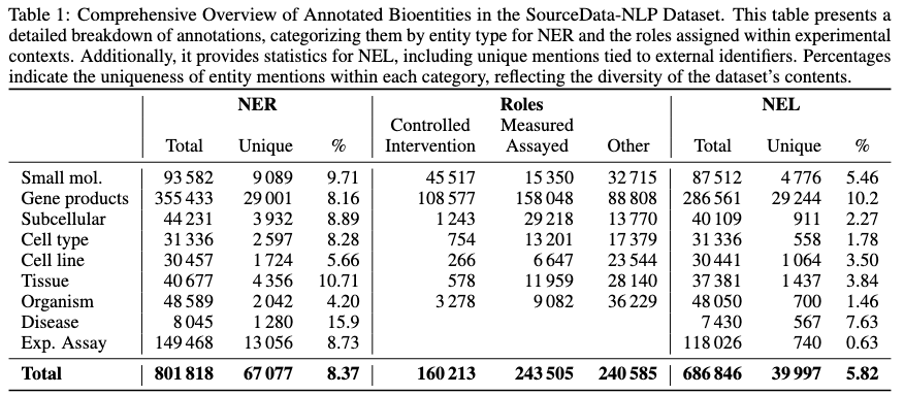
Tabla 1: Visión general completa de bioentidades anotadas en el dataset SourceData-NLP. La tabla presenta estadísticas detalladas para Reconocimiento de Entidades Nombradas (NER), asignaciones de roles experimentales y Vinculación de Entidades Nombradas (NEL) en todas las categorías de entidades. Los porcentajes de unicidad reflejan la diversidad de menciones de entidades, con ensayos experimentales mostrando la menor unicidad (0.63%) debido a metodologías repetidas, mientras que las moléculas pequeñas muestran la más alta (9.71%) reflejando diversos compuestos químicos estudiados en los artículos.
Lo que Anotamos
El dataset captura los elementos esenciales de la investigación biomédica:
Ocho tipos de entidades biológicas: moléculas pequeñas, productos génicos, componentes subcelulares, líneas celulares, tipos celulares, tejidos, organismos y enfermedades
Contexto experimental: Más allá de simplemente identificar entidades, anotamos sus roles en diseños experimentales y las metodologías utilizadas para estudiarlas
Relaciones semánticas: Cada entidad está vinculada a bases de datos autoritativas, permitiendo la desambiguación y conectando hallazgos a través de la literatura
Esta anotación granular, validada por los autores originales, asegura los datos de entrenamiento de más alta calidad para modelos de IA.
Por Qué Esto Importa
Integrar la curación en la publicación no se trata solo de construir un mejor dataset—se trata de repensar fundamentalmente cómo fluye el conocimiento científico. Cuando los datos estructurados se capturan en la fuente, están inmediatamente disponibles para:
Descubrimiento de Conocimiento
Los modelos de IA pueden identificar patrones y relaciones a través de millones de experimentos que ningún humano podría rastrear manualmente.
Investigación Acelerada
Los investigadores pueden consultar instantáneamente lo que se sabe sobre genes específicos, enfermedades o enfoques experimentales sin leer miles de artículos.
Reproducibilidad y Rigor
La anotación estandarizada de entidades durante la publicación ayuda a resolver ambigüedades terminológicas y conceptos poco claros antes de que se propaguen a través de la literatura.
Entrenamiento de IA a Escala
Los modelos de lenguaje grandes entrenados en SourceData-NLP entienden no solo la terminología biomédica, sino el contexto experimental en el que se hacen los descubrimientos.
Aplicaciones Derivadas
El dataset SourceData-NLP permite una nueva generación de herramientas de IA biomédica:
Inteligencia de Literatura
- Revisiones sistemáticas y meta-análisis automatizados
- Seguimiento de tendencias de investigación en tiempo real y análisis de brechas
- Síntesis de evidencia a través de décadas de publicaciones
Descubrimiento de Fármacos
- Identificación de objetivos novedosos mediante minería de relaciones de entidades
- Reutilización de fármacos conectando compuestos conocidos a nuevos contextos de enfermedades
- Predicción de efectos adversos a partir de literatura experimental
Traducción Clínica
- Vincular hallazgos de investigación básica a aplicaciones clínicas
- Construir grafos de conocimiento completos de enfermedad-gen-fármaco
- Apoyar la medicina de precisión con evidencia derivada de la literatura
Asistencia a la Investigación
- Recomendaciones de diseño experimental basadas en estudios similares
- Sugerencias de metodología para tipos de entidades específicos
- Generación de hipótesis a partir de co-ocurrencias inesperadas de entidades
Comprensión Científica
- Interpretación multimodal de figuras combinando imágenes y leyendas
- Extracción automatizada de protocolos y condiciones experimentales
- Seguimiento de la evolución de conceptos científicos a lo largo del tiempo
El Camino Hacia Adelante
SourceData-NLP demuestra que la curación integrada en la publicación no solo es factible sino transformadora. A medida que el dataset continúa creciendo con cada nueva publicación en EMBO Press, se convierte en un recurso cada vez más poderoso para entrenar modelos de IA que entienden los matices de la investigación biomédica.
Esto es más que un dataset—es un plan para cómo la publicación científica puede evolucionar para servir tanto a lectores humanos como a sistemas de IA, acelerando el ritmo del descubrimiento mientras mantiene el rigor que define la ciencia de calidad.
Herramientas y Tecnologías
El proyecto SourceData-NLP utiliza un stack completo de tecnologías modernas de IA y datos:
- HuggingFace Transformers - Modelos pre-entrenados e infraestructura de fine-tuning
- PyTorch - Framework de aprendizaje profundo para entrenamiento e inferencia de modelos
- Python - Lenguaje de programación principal para procesamiento de datos y desarrollo de modelos
- Computación GPU - Entrenamiento e inferencia acelerados para modelos de lenguaje grandes
- NLP - Pipelines de Procesamiento de Lenguaje Natural para reconocimiento y vinculación de entidades
- Neo4j - Base de datos de grafos para almacenamiento y consulta de grafos de conocimiento
- Base de Datos de Grafos - Almacenamiento y recuperación de relaciones semánticas entre entidades
Acceder al Dataset
- Artículo: arXiv:2310.20440
- EMBO en HuggingFace: HuggingFace - EMBO
- Dataset: HuggingFace - EMBO/SourceData
- Repositorio de Modelos: GitHub - soda-model
- Repositorio de Datos: GitHub - soda-data
Cita
@article{AbreuVicente2023,
title={The SourceData-NLP dataset: integrating curation into scientific publishing for training large language models},
author={Abreu-Vicente, Jorge and Sonntag, Hannah and Eidens, Thomas and Lemberger, Thomas},
journal={arXiv preprint arXiv:2310.20440},
year={2023},
month={October}
}
Al capturar el conocimiento en su fuente—el momento de la publicación—estamos construyendo la base para sistemas de IA que pueden verdaderamente entender y avanzar la investigación biomédica.